GlobalSearch can convert documents being captured to an Archive into the text-searchable PDF format through its Optional Full Page OCR module. (If you are licensed for this option.) Regardless of whether your document is a scanned, imported, or dragged into an Archive, documents are automatically converted behind the scenes. This feature does not convert documents that already texted-based, such as the DOCX file format. However, it will redo the OCR process for any PDFs that may already be text-searchable on each save operation. Keep this in mind, as it can have a significant impact on performance and document access.
Document types that are converted to PDF are: JPG, PNG, TIF, TIFF, PCX, TGA, BMP, WMF, EMF, PSD, WBMP, GIF, TLA, and PDF.
- To enable converting documents to text-editable PDF when creating a new Archive, enable Convert Documents to PDF in the New Archive dialog.
- To enable converting in an existing Archive, click Convert to PDF from the More Options (
 ) icon for the selected Archive.
) icon for the selected Archive.
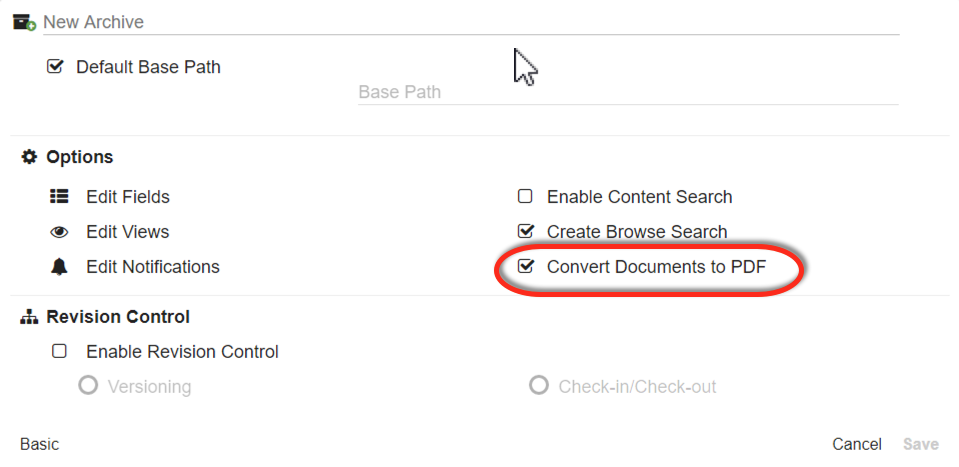
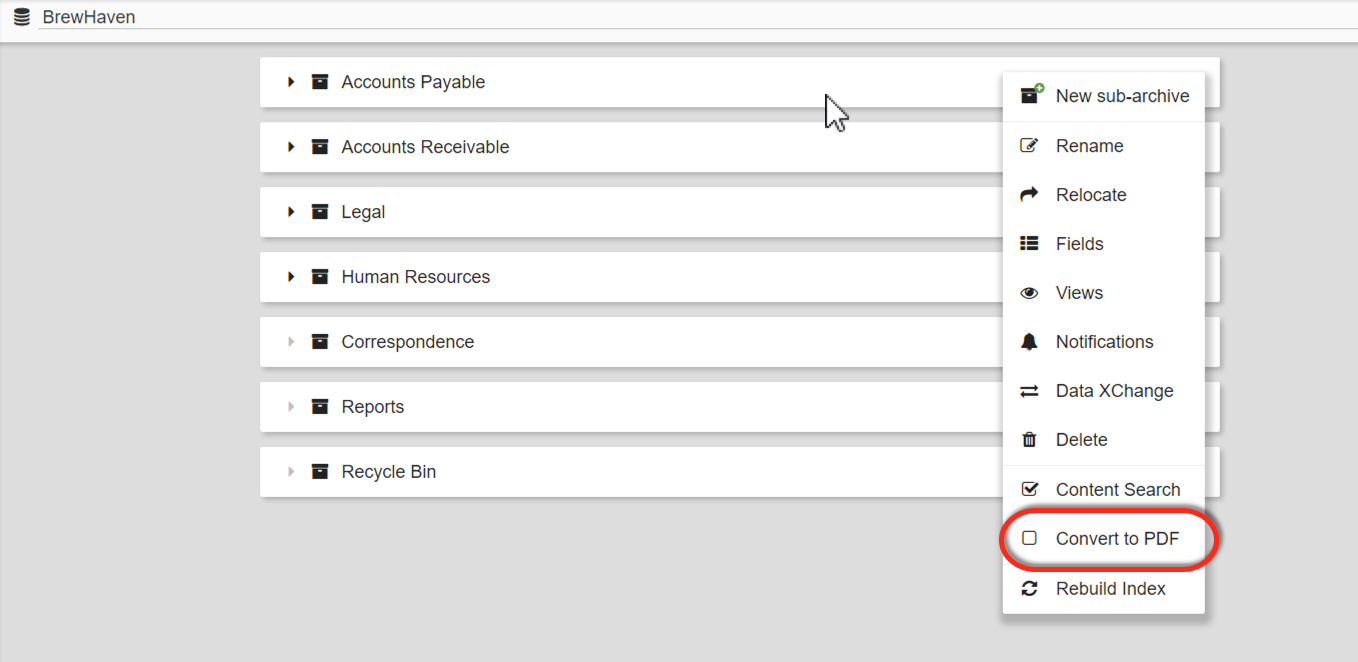
Remember to Make Your Archive Text Searchable
When converting your documents to text searchable PDF format, don't forget to enable the Archive for content-based searching so that the captured documents are indexed in the full-text database. With these features enabled, you will be able to build Content Searches for your user community.